Self-improving consensus agents
Some experiments using teams of agents to analyse the underlying structure of asynchronous assemblies

This is part of a wider initiative around observing, tracking and mapping the underlying structure of deliberative conversations that happen asynchronously via email. The first use case for this has been running series of assemblies designed to bring groups of stakeholders to consensus over the content of technical specifications. Here, I’ve created a team of agents whose collective task is to monitor, analyse and improve the underlying structure of the conversation - ultimately, we want to “see” the participants coming to consensus (or not). As the conversations are happening by email, a separate email client captures the response bodies, anonymises them and decomposes them into discrete “positions” or “ideas”. These positions are collected in a csv file for each round of deliberation.
This project processes text data from those ‘position’ CSV files and generates comprehensive analysis reports using a multi-agent system. It uses Mistral’s embedding model to create vector representations of text, applies dimensionality reduction and clustering to identify patterns, performs topic modelling to extract themes, and analyses sentiment. The results are then processed by five specialised AI agents working collaboratively. Interestingly, there’s a quasi-reinforcement learning process, where one agent reviews the work of the others and gives them feedback to incorporate in the subsequent rounds.
Meet the team
Whisper: Acts as a “team lead” - effectively a prompt engineer, designing prompts for the other agents to ensure high-quality outputs, coordinating the team and implementing recommendations from Critique, the quality control agent.
Spec: A software architect agent that examines the existing analysis script, identifies opportunities for enhancement, and writes technical specifications for additional analyses. They’re the agent who says, “We should add temporal trend analysis” or “Let’s validate the clustering with silhouette scores.”
Dev: A software engineer agent that implements Spec’s technical specifications as excutable Python code. Dev has access to a code interpreter tool, so they *execute* all the code—both the baseline analysis (embeddings, clustering, topic modeling, sentiment analysis) and any enhancements Spec suggests. Everything runs in a remote sandbox, with results captured via stdout.
Quant: A data analyst agent that interprets the results from Dev’s code execution, identifies key trends and insights, and generates detailed reports with actionable recommendations. They translate numbers into insights
Critique: After the pipeline completes, Critique audits *everything*: every prompt, every output, every line of code. She evaluates accuracy, clarity, code quality, and actionability. Then Critique generates learning materials for each agent—highlighting strengths, identifying weaknesses, providing resources, and updates the other agents’ prompts to incorporate lessons learned
The learning materials generated by Critique get saved and **accumulate** across runs. Each agent receives its full history of feedback every time it’s invoked.
Eventually this will integrate with the email client and other agents such that the assembly can be orchestrated and monitored agentically.
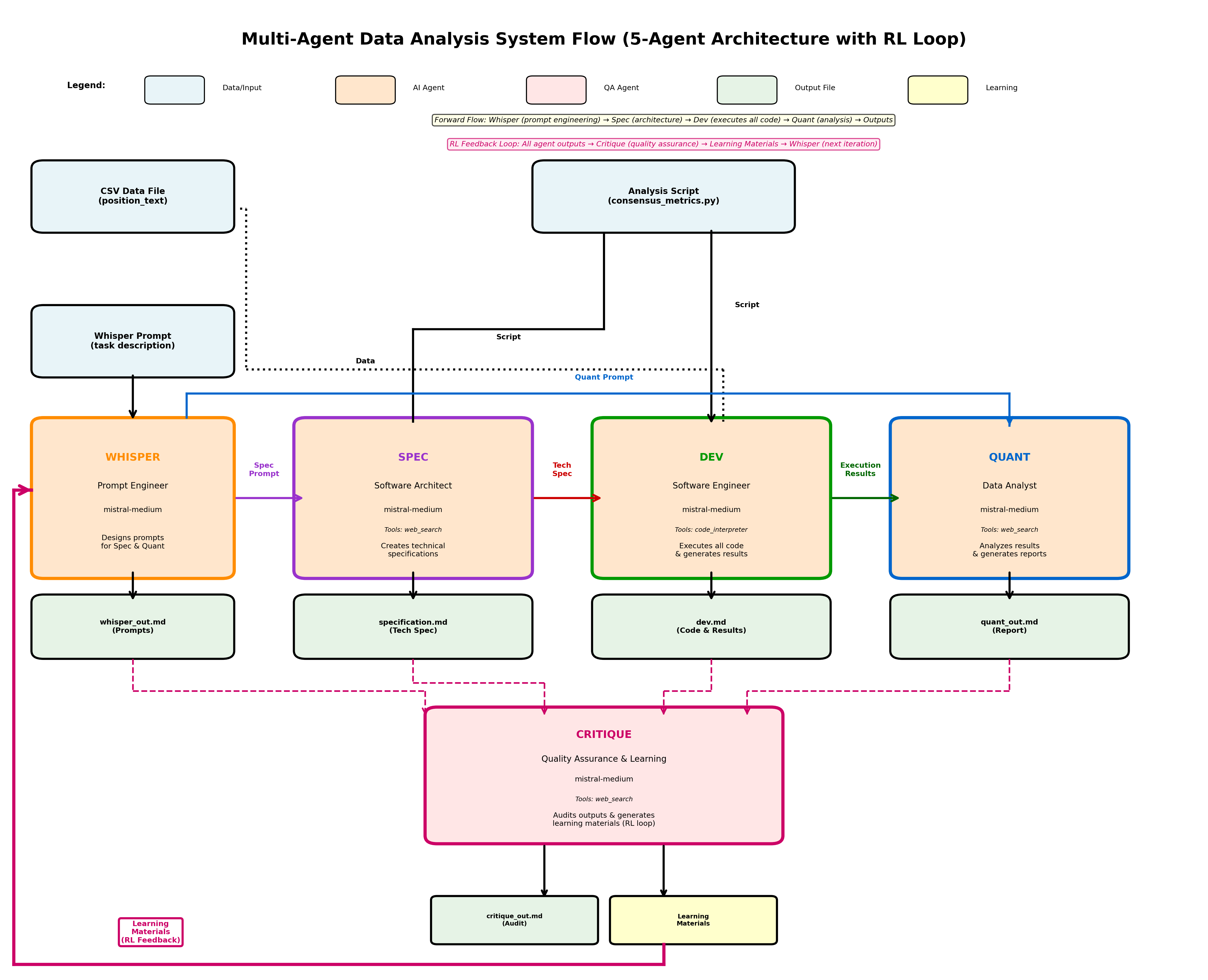
System Architecture
The diagram above illustrates the complete 5-agent architecture and information flow through the system.
The self improvement cycle
Reinforcement learning uses numerical rewards: +1 for good actions, -1 for bad ones. Here, I’m using qualitative, human-interpretable feedback instead. For example, when Dev writes code with poor error handling, Critique doesn’t just say “bad code: -0.5 reward.” Instead, she says something much richer in detail:
> “Your code lacks robust error handling. You should wrap file I/O operations in try-except blocks and validate data types before processing. See: [Python Error Handling Best Practices](https://docs.python.org/3/tutorial/errors.html)”
This feedback accumulates in a dedicated file that Dev reads on their next invocation, as context for their next coding task. On the next run, Dev’s prompt is prepended with something like:
## Lessons from Previous Runs
### Strengths
- Good modular structure with clear function definitions
- Effective use of pandas for data manipulation
### Areas for Improvement
- Add comprehensive error handling for file I/O...
- Implement data validation before processing...
- Use logging instead of print statements...
---
### Latest Feedback (Run 2)
- Excellent improvement on error handling!
- Still need better documentation...
What I’m attempting to do is to prod the system into self improvement without altering the model itself. AI systems typically improve through backpropagation—adjusting weights based on loss functions. This system improves through conversation, which is kind of a microcosm of what I built the entire system for in the first place - improving the efficacy of human conversations. Critique provides detailed, contextual feedback in natural language, and agents incorporate it into their behavior. No gradients, no loss functions, just agents reading their own performance reviews.
Every “reward” is a structured document explaining exactly what went right, what went wrong, and how to improve. The learning process is auditable simply by reading markdown files.
Unlike typical agent systems that start fresh each time, this system has memory across sessions. Learning materials accumulate like institutional knowledge.
This idea also goes another level deeper, since the feedback is given to the prompr engineer agent, Whisper, who incorporates it into the prom,pt design for the other agents in each round. Whisper’s own prompt gets tweaked by Critique after each run, and then Whisper updates the other agent’s prompts in turn. I’m not manually tuning prompts anymore - I just seed the initial prompt for Whisper and Critique in round 1 and from then on the system tunes itself.
Results from pilot study
I tested this on a small pilot study. A group of participants were asked 10 questions and their responses were freeform text submitted by email. I asked a preprocessing agent to analyse the responses and extract each unique position expressed in the response to a row in a csv file. This csv data was passed to the agent team for analysis. Here’s a snapshot of some of what they came up with (for brevity I’m not pasting entire outputs or Quant’s full report, just illustrative snippets).
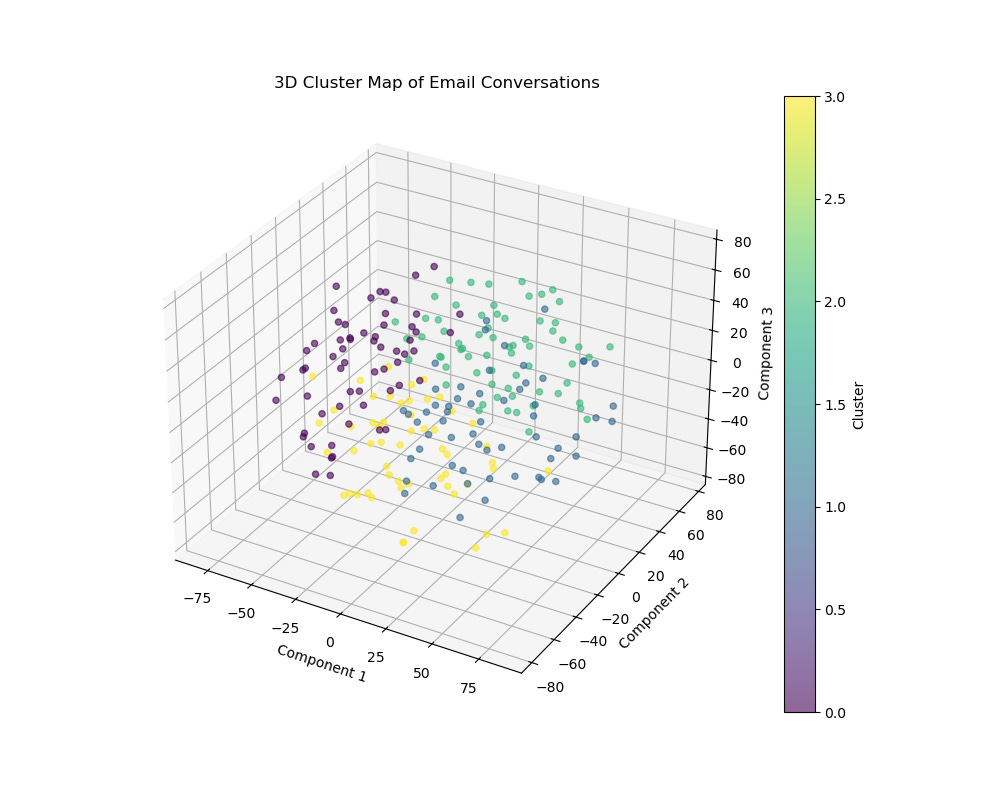
A cluster map of individual responses, after having been apssed through Mistral’s embeddings model, a tSNE dimensionality reduction and k-means cluster analysis (optimum number of clusters determined using Sillhouette score). This shows that the conversation was clustered around a few distinct themes. As the rounds of conversation progress, we might see these clusters converge, diverge, multiply or compress. We can use this to guide the conversation to focus on the right themes and monitor the consensus forming process.
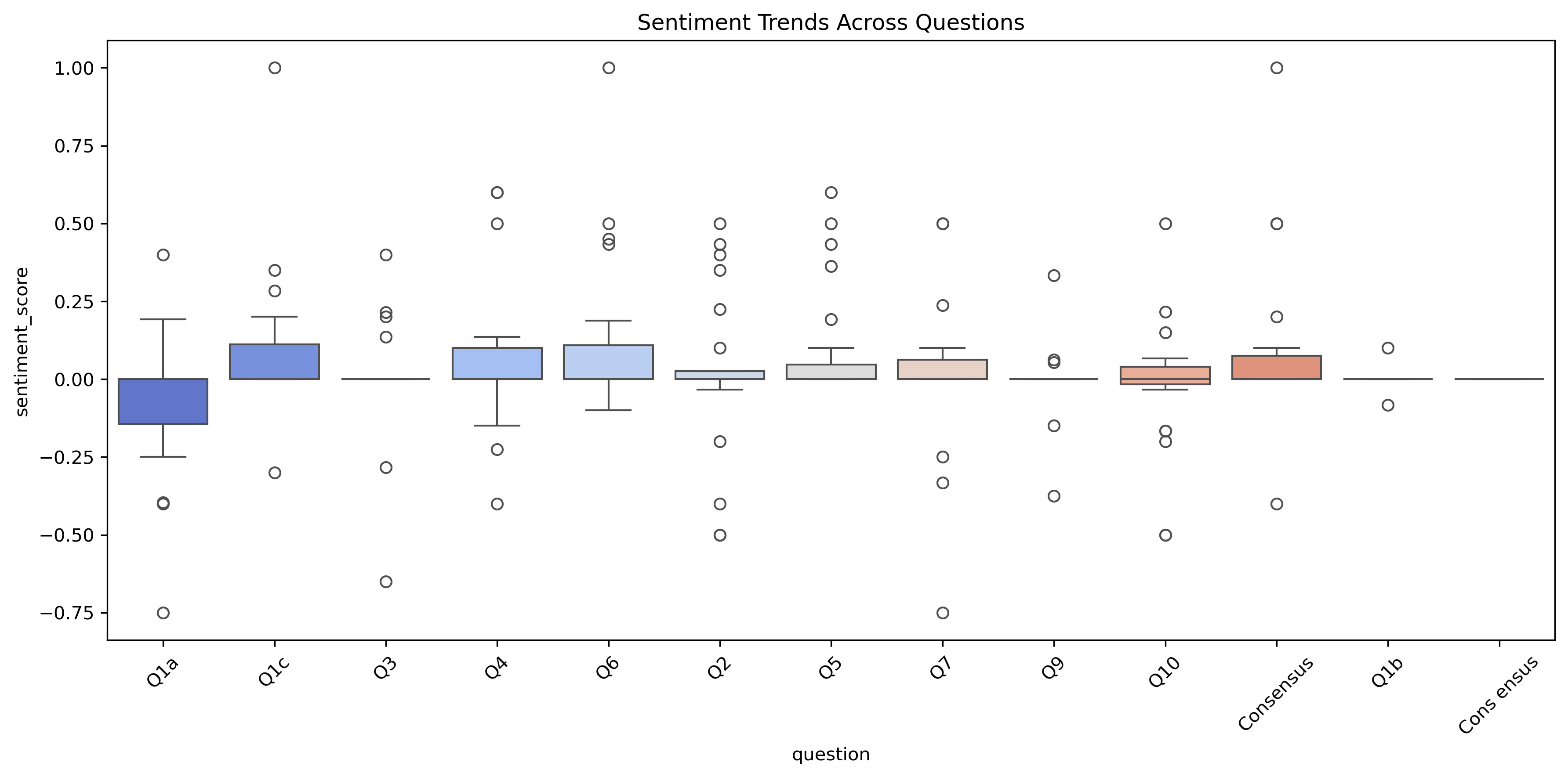
A mapping of sentiment analysis performed on the responses to each question, indicating which questions pleased or angered people the most, and where there was more harmony or polarisation among the group.
There were also several datasets and summary statistics generated, which were interpreted and reported by Quant, The report’s executive summary read as follows:
## **Executive Summary**
- **Thematic Convergence**: Thematic overlap between questions increased as discussions progressed, with the highest similarity (Jaccard score: 0.65) observed between Q1a and Q1c, indicating growing consensus on device inclusion and embodied carbon.
- **Sentiment Evolution**: Median sentiment improved from 0.1 (neutral/negative) in early rounds to 0.5 (positive) in later rounds, with statistically significant improvement (p=0.02, Kruskal-Wallis).
- **Participant Dynamics**: Participants `ffullone` and `cadams` consistently drove consensus (consistency score: 0.9), while `rpomado` and `dschein` showed higher volatility and dissent.
- **Key Themes**: “Device inclusion,” “embodied carbon,” and “boundary setting” dominated discussions, with “device inclusion” emerging as the most contentious but ultimately convergent theme.
- **Recommendations**: Prioritize device inclusion and embodied carbon in next steps; engage outliers (`rpomado`, `dschein`) for alignment; use tiered methodologies to balance simplicity and comprehensiveness.
Running the experiment multiple times, allowing the reinforcement loop to influence the outcomes, I observed the following:
**Run 1**: Dev generated basic visualisations with minimal error handling
**Run 2**: Dev added try-except blocks and data validation after Critique’s feedback
**Run 3**: Dev implemented logging and improved documentation
**Run 4**: Dev added support for larger datasets based on performance feedback
Quant’s reports got more specific: generic observations in Run 1 (”clustering reveals patterns”) evolved into actionable insights by Run 3 (”Cluster 2’s 23% representation suggests a significant minority viewpoint on carbon pricing that warrants focused discussion”).
This is only a small pilot study, but does seem to signify that they system is working as intended.
Limitations
The system as it stands has some quite major constraints, including:
- Mistral API has input size limits (~1-2MB), constraining how much data we can pass
- Dev runs in a remote sandbox—files saved there aren’t accessible locally - there’s some manual code execution required to e.g. generate visualizations.
- No file upload support in Mistral SDK v1.9.11; data must be string-embedded
- Sequential execution only (no parallel agent processing yet)
- Fixed analysis pipeline (embeddings → clustering → topics → sentiment)
I’m not sure exactly how these issues will resolve yet, but I think some combination of local embedding precomputation, chunk based processing and maybe adding in a coordinator agent that can decide when to call each agent would be beneficial. Some more elegant way to handle large datasets without resorting to sampling will also be important. I’d also like to add a trust agent that generates inclusion proofs and other assets that help users trust that their voice was heard and handled fairly in the synthesis - I think this will be very achievable using Mistral agents.
How does this connect to Harmony?
The primary use case for this is analysing text assets from deliberative assemblies orchestrated by an AI we refer to as “Harmony”. Scaling this requires Harmony to be able to:
1. **Scale without losing nuance**: Handle thousands of positions across multiple rounds
2. **Track evolution**: Show how consensus forms or fractures over time
3. **Surface marginalized voices**: Identify minority viewpoints that might be valuable
4. **Generate actionable insights**: Not just “here are clusters” but “cluster 3 suggests you need focused discussion on Topic X”
The system I described above only tackles points 2 and 4 - monitoring consensus and generating actionable insights, but it does so in a way that self improves every time it is run. The agent team can later be expanded to cover more of the assembly until the entire end-to-end process is agentic, with human interaction being mostly monitoring and course-correction.
Right now the pieces are coming together but they’re not tightly integrated. I’m very much experimenting here, and may find that I’ve gone down some blind alleys.
The code for this multi-agent system is here: https://github.com/jmcook1186/mistral-data-agent